
Computing Eulerian paths is harder than you think
Share onEveryone who has studied any graph theory at all knows the celebrated story of the Seven Bridges of Königsberg, and how Euler gave birth to modern graph theory while solving the problem.
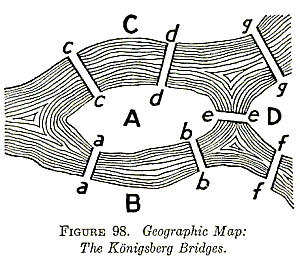
Euler’s proof is clever, incisive, not hard to understand, and a great introduction to the kind of abstract reasoning we can do about graphs. There’s little wonder that it is often used as one of the first nontrivial graph theory results students are introduced to, e.g. in a discrete mathematics course. (Indeed, I will be teaching discrete mathematics in the spring and certainly plan to talk about Eulerian paths!)
Euler’s 1735 solution was not constructive, and in fact he really only established one direction of the “if and only if”:
If a graph has an Eulerian path, then it has exactly zero or two vertices with odd degree.
This can be used to rule out the existence of Eulerian paths in graphs without the right vertex degrees, which was Euler’s specific motivation. However, one suspects that Euler knew it was an if and only if, and didn’t write about the other direction (if a graph has exactly zero or two vertices with odd degree, then it has an Eulerian path) because he thought it was trivial.1
The first person to publish a full proof of both directions, including an actual algorithm for finding an Eulerian path, seems to be Carl Hierholzer, whose friend published a posthumous paper in Hierholzer’s name after his untimely death in 1871, a few weeks before his 31st birthday.2 (Notice that this was almost 150 years after Euler’s original paper!) If the vertex degrees cooperate, finding an Eulerian path is almost embarrassingly easy according to Hierholzer’s algorithm: starting at one of the odd-degree vertices (or anywhere you like if there are none), just start walking through the graph—any which way you please, it doesn’t matter!—visiting each edge at most once, until you get stuck. Then pick another part of the graph you haven’t visited, walk through it randomly, and splice that path into your original path. Repeat until you’ve explored the whole graph. And generalizing all of this to directed graphs isn’t much more complicated.
So, in summary, this is a well-studied problem, solved hundreds of years ago, that we present to students as a first example of a nontrivial yet still simple-to-understand graph proof and algorithm. So it should be pretty easy to code, right?
So what’s the problem?
Recently I came across the eulerianpath problem on Open Kattis, and I realized that although I have understood this algorithm on a theoretical level for almost two decades (I almost certainly learned it as a young undergraduate), I have never actually implemented it! So I set out to solve it.
Right away the difficulty rating of 5.7 tells us that something strange is going on. “Easy” problems—the kind of problems you can give to an undergraduate at the point in their education when they might first be presented with the problem of finding Eulerian paths—typically have a difficulty rating below 3. As I dove into trying to implement it, I quickly realized two things. First of all, given an arbitrary graph, there’s a lot of somewhat finicky work that has to be done to check whether the graph even has an Eulerian path, before running the algorithm proper:
- Calculate the degree of all graph vertices (e.g. by iterating through all the edges and incrementing appropriate counters for the endpoints of each edge).
- Check if the degrees satisfy Euler’s criteria for the existence of a solution, by iterating through all vertices and making sure their degrees are all even, but also counting the number of vertices with an odd degree to make sure it is either zero or two. At the same time, if we see an odd-degree vertex, remember it so we can be sure to start the path there.
- If all vertices have even degree, pick an arbitrary node as the start vertex.
- Ensure the graph is connected (e.g. by doing a depth-first search)—Euler kind of took this for granted, but this technically has to be part of a correct statement of the theorem. If we have a disconnected graph, each component could have an Eulerian path or cycle without the entire graph having one.
And if the graph is directed—as it is in the eulerianpath problem on Kattis—then the above steps get even more finicky. In step 1, we have to count the in- and outdegree of each vertex separately; in step 2, we have to check that the in- and outdegrees of all vertices are equal, except for possibly two vertices where one of them has exactly one more outgoing than incoming edge (which must be the start vertex), and vice versa for the other vertex; in step 4, we have to make sure to start the DFS from the chosen start vertex, because the graph need not be strongly connected, it’s enough for the entire graph to be reachable from the start vertex.
The second thing I realized is that Hierholzer’s algorithm proper—walk around until getting stuck, then repeatedly explore unexplored parts of the graph and splice them into the path being built—is still rather vague, and it’s nontrivial to figure out how to do it, and what data structures to use, so that everything runs in time linear in the number of edges. For example, we don’t want to iterate over the whole graph—or even just the whole path built so far—to find the next unexplored part of the graph every time we get stuck. We also need to be able to do the path splicing in constant time; so, for example, we can’t just store the path in a list or array, since then splicing in a new path segment would require copying the entire path after that point to make space. I finally found a clever solution that pushes the nodes being explored on a stack; when we get stuck, we start popping nodes, placing them into an array which will hold the final path (starting from the end), and keep popping until we find a node with an unexplored outgoing edge, then switch back into exploration mode, pushing things on the stack until we get stuck again, and so on. But this is also nontrivial to code correctly since there are many lurking off-by-one errors and so on. And I haven’t even talked about how we keep track of which edges have been explored and quickly find the next unexplored edge from a vertex.
I think it’s worth writing another blog post or two with more details of how the implementation works, both in an imperative language and in a pure functional language, and I may very well do just that. But in any case, what is it about this problem that results in such a large gap between the ease of understanding its solution theoretically, and the difficulty of actually implementing it?
-
Actually, the way I have stated the other direction of the if and only if is technically false!—can you spot the reason why?↩︎
-
Though apparently someone named Listing published the basic idea of the proof, with some details omitted, some decades earlier. I’ve gotten all this from Herbert Fleischner, Eulerian Graphs and Related Topics, Annals of Discrete Mathematics 45, Elsevier 1990. Fleischner reproduces Euler’s original paper as well as Hierholzer’s, together with English translations.↩︎